Atenção
Migramos este artigo para o novo site:
 http://www.sqlfromhell.com/usuarios-orfaos-gerando-o-script-de-create-login-com-os-sids/
http://www.sqlfromhell.com/usuarios-orfaos-gerando-o-script-de-create-login-com-os-sids/
http://www.sqlfromhell.com/usuarios-orfaos-gerando-o-script-de-create-login-com-os-sids/
Se você tem menos de 18 anos, ou sofre de problemas cardíacos, ou não tem certeza sobre suas convicções religiosas, ou não manja de UPDATE, então NÃO PROSSIGA.
Eu e o Márcio Gomes, em uma discussão sobre SQL (o que nunca dá bons resultados), nos deparamos com o bendito do ‘WHERE 1=1’, que em um momento de insanidade transformamos em ‘WHERE SQRT(SQUARE(1 + 1)) * 3 = 6’. Para testar o fruto desta capacidade criativa, optamos por comparar planos de execução, de uma query sem WHERE, outra com o ‘WHERE 1=1’ e outra com ‘WHERE SQRT(SQUARE(1 + 1)) * 3 = 6’.
Veja como ‘WHERE SQRT(SQUARE(1 + 1)) * 3 = 6’ tem menor custo que as outras consultas: #sqn
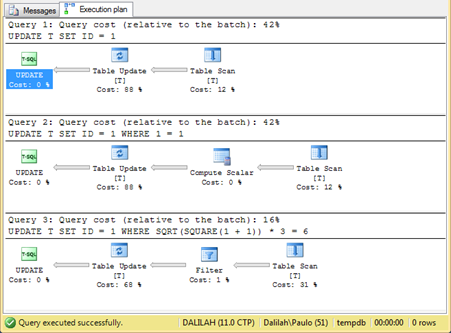
Enganamos o plano de execução do SQL? Onde está seu deus agora?
Para quem duvida, segue o script:
CREATE TABLE T (ID INT NOT NULL, TXT CHAR(32) NOT NULL)
;WITH CTE (ID) AS (
SELECT 1
UNION ALL
SELECT ID + 1 FROM CTE WHERE ID < 100000
)
INSERT INTO T
SELECT ID, REPLICATE('0', 32) FROM CTE
OPTION (MAXRECURSION 0)
UPDATE T SET ID = 1
UPDATE T SET ID = 1 WHERE 1 = 1
UPDATE T SET ID = 1 WHERE SQRT(SQUARE(1 + 1)) * 3 = 6
Olá pessoas,
Após conhecer um pouco do UNPIVOT, percebe-se que este comando não é muito flexível, mesmo sendo um pouco mais maleável que o comando PIVOT. Por desconhecer este comando, ou pela falta de flexibilidade, é comum encontrar outras alternativas para ‘transformar colunas em linhas’, como o exemplo abaixo:
-- Criando uma tabela de teste:
DECLARE @CONTAS TABLE (
[BANCO] VARCHAR(100),
[ANO] SMALLINT,
[INVESTIMENTOS] MONEY,
[DESPESAS] MONEY
)
INSERT INTO @CONTAS VALUES
('BANCO ALVORADA S/A', 2010, 9613906084.01, 8102644.84),
('BANCO ALVORADA S/A', 2011, 174343.35, 7935411.15),
('BANCO ARBI S/A', 2010, 8202652.29, 114215.13),
('BANCO ARBI S/A', 2011, 8407843.72, 81746.25)
-- Uso do UNION ALL para transformar colunas em linhas:
SELECT [BANCO], [ANO], 'INVESTIMENTOS' AS [TIPO], C.[INVESTIMENTOS] AS [VALOR] FROM @CONTAS C
UNION ALL
SELECT [BANCO], [ANO], 'DESPESAS' AS [TIPO], C.[DESPESAS] AS [VALOR] FROM @CONTAS C
ORDER BY [BANCO], [ANO], [TIPO]
Esta estratégia com UNION ALL requer uma leitura da tabela a mais para cada coluna transformada em linha, ou seja, a tabela no exemplo acima foi lida duas vezes para obter o mesmo resultado que poderia ser obtido lendo a tabela uma única vez com UNPIVOT:
SELECT [BANCO], [ANO], [TIPO], [VALOR]
FROM @CONTAS C
UNPIVOT (
[VALOR] FOR [TIPO] IN (
[INVESTIMENTOS],
[DESPESAS]
)
) AS U
ORDER BY [BANCO], [ANO], [TIPO]
Com o STATISTICS IO, podemos obter as seguintes informações:
Consulta com UNION ALL:
(8 row(s) affected)
Table ‘#A255182D’. Scan count 2, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Consulta com UNPIVOT:
(8 row(s) affected)
Table ‘#A255182D’. Scan count 1, logical reads 1, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Mas como obter flexibilidade, tendo um número de leituras semelhante ao UNPIVOT, e até mesmo ter um plano de execução um pouco melhor?
A resposta pode ser encontrada no CROSS APPLY – que para quem não conhece, este comando funciona de forma um pouco semelhante ao JOIN, executando uma determinada subquery para cada registro da tabela com a qual ele faz o ‘JOIN’ –, que pode ser utilizado com UNION ALL para transformar colunas em linhas:
SELECT [BANCO], [ANO], [TIPO], [VALOR]
FROM @CONTAS C
CROSS APPLY (
SELECT 'INVESTIMENTOS' AS [TIPO], C.[INVESTIMENTOS] AS [VALOR]
UNION ALL
SELECT 'DESPESAS' AS [TIPO], C.[DESPESAS] AS [VALOR]
)
AS U
ORDER BY [BANCO], [ANO], [TIPO]
Ou combinado ao VALUES:
SELECT [BANCO], [ANO], [TIPO], [VALOR]
FROM @CONTAS C
CROSS APPLY (
VALUES
('INVESTIMENTOS', C.[INVESTIMENTOS]),
('DESPESAS', C.[DESPESAS])
)
AS U ([TIPO], [VALOR])
ORDER BY [BANCO], [ANO], [TIPO]
Em breve, vou publicar um comparativo mais detalhado entre o UNPIVOT e o CROSS APPLY!
Olá pessoas,
A partir desta semana, o Márcio Gomes terá um espaço para expressar todo seu amor ao SQL, então boa diversão!
Antes de tudo eu gostaria de agradecer ao Paulo pelo espaço cedido no SQL FROM HELL, não existe lugar melhor na internet para eu expressar meus sentimentos em relação ao SQL.
Que eu ODEIO SQL todo mundo sabe, no entanto o que pouca gente sabe é que o SQL ME ODEIA! Sim… essa relação de guerra e paz começou em 2002 e segue até hoje e posso garantir com todas as letras, o SQL não perde uma única chance de me sacanear, quando tudo parece que vai dar certo de repente algo sobrenatural acontece e somente recorrendo à ajuda do Paulo combinado com duas velas pretas na encruzilhada as coisas voltam ao normal.
Hoje como é a estreia dos relatos sobre a guerra cotidiana tentando sobreviver aos ataques terroristas do SQL Server deixo um print screen mostrando que o .NET Framework concorda comigo.

Exatamente isto que você leu meu caro amigo “NO BANDO DE DADOS” (sic), o SQL é uma espécie de clã, horda, bando de dados armados que criam batalhas digitais que nos post futuros serão descritas aqui no SQL FROM HELL!
E ai pessoas, revisando o script de validação de CPF e CNPJ em T-SQL que adaptei em 2009, encontrei algumas melhorias pra deixá-lo mais limpo, espero que gostem:
DECLARE @TEXTO VARCHAR(20) = '02.841.834/0001-55' DECLARE @CPF_CNPJ VARCHAR(20) = '' ;WITH SPLIT AS ( SELECT 1 AS ID, SUBSTRING(@TEXTO, 1, 1) AS LETRA UNION ALL SELECT ID + 1, SUBSTRING(@TEXTO, ID + 1, 1) FROM SPLIT WHERE ID < LEN(@TEXTO) ) SELECT @CPF_CNPJ += LETRA FROM SPLIT WHERE LETRA LIKE '[0-9]' OPTION(MAXRECURSION 0) IF LEN(@CPF_CNPJ) NOT IN (11, 14) BEGIN SELECT 'Inválido' RETURN END DECLARE @I INT, @J INT = 1, @N INT = LEN(@CPF_CNPJ), @DIGITO1 INT = SUBSTRING(@CPF_CNPJ, LEN(@CPF_CNPJ) - 1, 1), @DIGITO2 INT = SUBSTRING(@CPF_CNPJ, LEN(@CPF_CNPJ), 1), @TOTAL_TMP INT, @COEFICIENTE_TMP INT, @DIGITO_TMP INT, @VALOR_TMP INT, @VALOR1 INT, @VALOR2 INT WHILE @J <= 2 BEGIN SELECT @TOTAL_TMP = 0, @COEFICIENTE_TMP = 2, @I = @N + @J - 3 WHILE @I >= 0 BEGIN SELECT @DIGITO_TMP = SUBSTRING(@CPF_CNPJ, @I, 1), @TOTAL_TMP += @DIGITO_TMP * @COEFICIENTE_TMP, @COEFICIENTE_TMP = @COEFICIENTE_TMP + 1, @I -= 1 IF @COEFICIENTE_TMP > 9 AND @N = 14 SET @COEFICIENTE_TMP = 2 END SET @VALOR_TMP = 11 - (@TOTAL_TMP % 11) IF (@VALOR_TMP >= 10) SET @VALOR_TMP = 0 IF @J = 1 SET @VALOR1 = @VALOR_TMP ELSE SET @VALOR2 = @VALOR_TMP SET @J += 1 END SELECT CASE WHEN @VALOR1 = @DIGITO1 AND @VALOR2 = @DIGITO2 THEN 'Válido' ELSE 'Inválido' END
E o script para criar uma função de validação de CPF e CNPJ:
CREATE FUNCTION [dbo].[UDF_ValidaCpfCnpj] (@TEXTO VARCHAR(20))
RETURNS BIT
AS
BEGIN
DECLARE @CPF_CNPJ VARCHAR(20) = ''
;WITH SPLIT AS
(
SELECT 1 AS ID, SUBSTRING(@TEXTO, 1, 1) AS LETRA
UNION ALL
SELECT ID + 1, SUBSTRING(@TEXTO, ID + 1, 1)
FROM SPLIT
WHERE ID < LEN(@TEXTO)
)
SELECT @CPF_CNPJ += LETRA
FROM SPLIT
WHERE LETRA LIKE '[0-9]'
OPTION(MAXRECURSION 0)
IF LEN(@CPF_CNPJ) NOT IN (11, 14)
BEGIN
RETURN 0
END
DECLARE
@I INT,
@J INT = 1,
@N INT = LEN(@CPF_CNPJ),
@DIGITO1 INT = SUBSTRING(@CPF_CNPJ, LEN(@CPF_CNPJ) - 1, 1),
@DIGITO2 INT = SUBSTRING(@CPF_CNPJ, LEN(@CPF_CNPJ), 1),
@TOTAL_TMP INT,
@COEFICIENTE_TMP INT,
@DIGITO_TMP INT,
@VALOR_TMP INT,
@VALOR1 INT,
@VALOR2 INT
WHILE @J <= 2
BEGIN
SELECT
@TOTAL_TMP = 0,
@COEFICIENTE_TMP = 2,
@I = @N + @J - 3
WHILE @I >= 0
BEGIN
SELECT
@DIGITO_TMP = SUBSTRING(@CPF_CNPJ, @I, 1),
@TOTAL_TMP += @DIGITO_TMP * @COEFICIENTE_TMP,
@COEFICIENTE_TMP = @COEFICIENTE_TMP + 1,
@I -= 1
IF @COEFICIENTE_TMP > 9 AND @N = 14
SET @COEFICIENTE_TMP = 2
END
SET @VALOR_TMP = 11 - (@TOTAL_TMP % 11)
IF (@VALOR_TMP >= 10)
SET @VALOR_TMP = 0
IF @J = 1
SET @VALOR1 = @VALOR_TMP
ELSE
SET @VALOR2 = @VALOR_TMP
SET @J += 1
END
RETURN
CASE WHEN @VALOR1 = @DIGITO1 AND @VALOR2 = @DIGITO2
THEN 1
ELSE 0
END
END
GO
SELECT CASE
WHEN [dbo].[UDF_ValidaCpfCnpj] ('02.841.834/0001-55') = 1
THEN 'Válido'
ELSE 'Inválido'
END
E um segundo script para criar uma função de validação de CPF e CNPJ, considerando que o CPF ou CNPJ que a função vai receber nunca terá caracteres especiais ou mais/menos dígitos que um CPF ou CNPJ possui:
CREATE FUNCTION [dbo].[UDF_ValidaCpfCnpj] (@CPF_CNPJ VARCHAR(20))
RETURNS BIT
AS
BEGIN
DECLARE
@I INT,
@J INT = 1,
@N INT = LEN(@CPF_CNPJ),
@DIGITO1 INT = SUBSTRING(@CPF_CNPJ, LEN(@CPF_CNPJ) - 1, 1),
@DIGITO2 INT = SUBSTRING(@CPF_CNPJ, LEN(@CPF_CNPJ), 1),
@TOTAL_TMP INT,
@COEFICIENTE_TMP INT,
@DIGITO_TMP INT,
@VALOR_TMP INT,
@VALOR1 INT,
@VALOR2 INT
WHILE @J <= 2
BEGIN
SELECT
@TOTAL_TMP = 0,
@COEFICIENTE_TMP = 2,
@I = @N + @J - 3
WHILE @I >= 0
BEGIN
SELECT
@DIGITO_TMP = SUBSTRING(@CPF_CNPJ, @I, 1),
@TOTAL_TMP += @DIGITO_TMP * @COEFICIENTE_TMP,
@COEFICIENTE_TMP = @COEFICIENTE_TMP + 1,
@I -= 1
IF @COEFICIENTE_TMP > 9 AND @N = 14
SET @COEFICIENTE_TMP = 2
END
SET @VALOR_TMP = 11 - (@TOTAL_TMP % 11)
IF (@VALOR_TMP >= 10)
SET @VALOR_TMP = 0
IF @J = 1
SET @VALOR1 = @VALOR_TMP
ELSE
SET @VALOR2 = @VALOR_TMP
SET @J += 1
END
RETURN
CASE WHEN @VALOR1 = @DIGITO1 AND @VALOR2 = @DIGITO2
THEN 1
ELSE 0
END
END
GO
SELECT
CASE WHEN [dbo].[UDF_ValidaCpfCnpj] ('02841834000155') = 1
THEN 'Válido'
ELSE 'Inválido'
END
Quem tiver alguma dica ou sugestão pra melhorar este script, fique a vontade para deixar seu comentário.
Artigos relacionados:
FUNÇÕES: Validação de CNPJ e CPF com T-SQL
FUNÇÕES: Somente Números (com CTE)
FUNÇÕES: Somente Números (com WHILE)
Olá pessoas,
O UNPIVOT é um pouco menos conhecido que o PIVOT, por razões óbvias, dentre elas, “é fácil transformar colunas em linhas”. Mas isso não limita o fato de quem já está acostumado com PIVOT, também utilize o UNPIVOT como recurso, principalmente por apresentarem sintaxes bem semelhantes.
UNPIVOT não utiliza funções de agregação como o PIVOT, mas é necessária capacidade abstrair duas colunas, sendo a primeira, a coluna que apresentará o nome da coluna que virou linha, e a segunda, a coluna que apresentará o valor da coluna que virou linha.
Para o primeiro exemplo, temos uma tabela com as colunas INVESTIMENTOS e DESPESAS, e transformo ‘investimentos’ e ‘despesas’ em valores da coluna TIPO, e os valores destas colunas coloco na coluna VALOR:
DECLARE @CONTAS TABLE (
[BANCO] VARCHAR(100),
[ANO] SMALLINT,
[INVESTIMENTOS] MONEY,
[DESPESAS] MONEY
)
INSERT INTO @CONTAS VALUES
('BANCO ALVORADA S/A', 2010, 9613906084.01, 8102644.84),
('BANCO ALVORADA S/A', 2011, 174343.35, 7935411.15),
('BANCO ARBI S/A', 2010, 8202652.29, 114215.13),
('BANCO ARBI S/A', 2011, 8407843.72, 81746.25)
SELECT [BANCO], [ANO], [TIPO], [VALOR]
FROM @CONTAS C
UNPIVOT (
[VALOR] FOR [TIPO] IN (
[INVESTIMENTOS],
[DESPESAS]
)
) AS U
ORDER BY [BANCO], [ANO], [TIPO]

Para o segundo exemplo, temos uma tabela com as colunas 2010 e 2011, e transformo ‘2010’ e ‘2011’ em valores da coluna ANO, e os valores destas colunas coloco na coluna VALOR:
DECLARE @CONTAS TABLE (
[BANCO] VARCHAR(100),
[TIPO] VARCHAR(100),
[2010] MONEY,
[2011] MONEY
)
INSERT INTO @CONTAS VALUES
('BANCO ALVORADA S/A', 'INVESTIMENTOS', 9613906084.01, 174343.35),
('BANCO ALVORADA S/A', 'DESPESAS', 8102644.84, 7935411.15),
('BANCO ARBI S/A', 'INVESTIMENTOS', 8202652.29, 8407843.72),
('BANCO ARBI S/A', 'DESPESAS', 114215.13, 81746.25)
SELECT [BANCO], [ANO], [TIPO], [VALOR]
FROM @CONTAS C
UNPIVOT (
[VALOR] FOR [ANO] IN (
[2010],
[2011]
)
) AS U
ORDER BY [BANCO], [ANO], [TIPO]

Para este terceiro exemplo, temos colunas juntos os nomes são formados tanto pelo tipo da conta e o ano, o que requer algumas transformações nos valores da coluna CONTA, para identificarmos o ano e o tipo da conta.
DECLARE @CONTAS TABLE (
[BANCO] VARCHAR(100),
[INVESTIMENTOS_2010] MONEY,
[INVESTIMENTOS_2011] MONEY,
[DESPESAS_2010] MONEY,
[DESPESAS_2011] MONEY
)
INSERT INTO @CONTAS VALUES
('BANCO ALVORADA S/A', 9613906084.01, 8102644.84,
174343.35, 7935411.15),
('BANCO ARBI S/A',8202652.29, 114215.13,
8407843.72, 81746.25)
SELECT [BANCO],
[ANO] = RIGHT([CONTA], CHARINDEX('_', REVERSE([CONTA])) - 1),
[TIPO] = LEFT([CONTA], CHARINDEX('_', [CONTA]) - 1),
[VALOR]
FROM @CONTAS C
UNPIVOT (
[VALOR] FOR [CONTA] IN (
[INVESTIMENTOS_2010],
[INVESTIMENTOS_2011],
[DESPESAS_2010],
[DESPESAS_2011]
)
) AS U
ORDER BY [BANCO], [ANO], [TIPO]

Agora, neste quarto exemplo, temos a transformação de diversas colunas em registros, o que requer unicamente que estas colunas sejam do mesmo tipo, no caso VARCHAR(100), para não dar o erro:
The type of column “xxxxx” conflicts with the type of other columns specified in the UNPIVOT list.
DECLARE @CONTAS TABLE (
[BANCO] VARCHAR(100),
[ANO] SMALLINT,
[INVESTIMENTOS] MONEY,
[DESPESAS] MONEY
)
INSERT INTO @CONTAS VALUES
('BANCO ALVORADA S/A', 2010, 9613906084.01, 8102644.84),
('BANCO ALVORADA S/A', 2011, 174343.35, 7935411.15),
('BANCO ARBI S/A', 2010, 8202652.29, 114215.13),
('BANCO ARBI S/A', 2011, 8407843.72, 81746.25)
SELECT [COLUNA], [VALOR]
FROM (
SELECT
[BANCO],
[ANO] = CAST([ANO] AS VARCHAR(100)),
[INVESTIMENTOS] = CAST([INVESTIMENTOS] AS VARCHAR(100)),
[DESPESAS] = CAST([DESPESAS] AS VARCHAR(100))
FROM @CONTAS
) C
UNPIVOT (
[VALOR] FOR [COLUNA] IN (
[INVESTIMENTOS],
[DESPESAS],
[BANCO],
[ANO]
)
) AS U

Boa noite pessoas,
Como apareceu uma questão nos artigos de FOR XML, sobre como atribuir uma consulta resultante de um FOR XML como valor de uma variável no SQL Server, elaborei estes dois exemplos.
O primeiro: uma variável do tipo XML (@X), o segundo: uma variável do tipo VARCHAR (@C).

Este exemplo é útil para vincular os artigos de FOR XML com os artigos de XQUERY, já que eu não tinha utilizado nos artigos de XQUERY nenhum exemplo cujo o valor da variável era gerado por FOR XML.
Espero que tenham gostado!
Artigos relacionados
Gerando XML no SQL Server – Arte do FOR XML AUTO
Gerando XML no SQL Server – Arte do FOR XML EXPLICIT
Gerando XML no SQL Server – Arte do FOR XML RAW
Gerando XML no SQL Server – Arte do FOR XML PATH
Iniciando com XQuery – Lendo XML no SQL Server
Iniciando com XQuery – Gerando XML no SQL Server
Iniciando com XQuery – Modificando XML no SQL Server
Iniciando com XQuery – Namespaces têm solução!
Olá pessoas,
Na semana passada, nós vimos como transformar linhas em colunas no SQL Server com PIVOT. Mas como nem sempre dá para contar com este recurso, e algumas vezes, ele não supre 100% das nossas necessidades, vou apresentar alguns exemplos de como fazer PIVOT sem utilizar PIVOT.
Para estes exemplos, estarei utilizando da mesma massa de dados da semana anterior:
DECLARE @CONTAS TABLE ( ANO SMALLINT, BANCO VARCHAR(100), TIPO VARCHAR(100), VALOR MONEY ) INSERT INTO @CONTAS VALUES (2009,'BANCO ALVORADA S/A','INVESTIMENTOS',6175979775.42), (2010,'BANCO ALVORADA S/A','INVESTIMENTOS',6486892688.53), (2011,'BANCO ALVORADA S/A','INVESTIMENTOS',7905663406.86), (2012,'BANCO ALVORADA S/A','INVESTIMENTOS',9613906084.01), (2009,'BANCO ARBI S/A','INVESTIMENTOS',8102644.84), (2009,'BANCO ARBI S/A','OUTROS',174343.35), (2010,'BANCO ARBI S/A','INVESTIMENTOS',7935411.15), (2010,'BANCO ARBI S/A','OUTROS',119885.82), (2011,'BANCO ARBI S/A','INVESTIMENTOS',8202652.29), (2011,'BANCO ARBI S/A','OUTROS',114215.13), (2012,'BANCO ARBI S/A','INVESTIMENTOS',8407843.72), (2012,'BANCO ARBI S/A','OUTROS',81746.25)
Conforme o primeiro exemplo da semana anterior, transformamos os registros de contas do tipo INVESTIMENTOS e OUTROS em duas colunas, utilizando PIVOT:
SELECT U.ANO, U.BANCO, U.INVESTIMENTOS, U.OUTROS FROM @CONTAS AS C PIVOT ( SUM(C.VALOR) FOR C.TIPO IN (INVESTIMENTOS, OUTROS) ) AS U
Sem PIVOT, é possível fazer o mesmo procedimento com CASE WHEN:
SELECT C.ANO, C.BANCO, INVESTIMENTOS = SUM(CASE WHEN C.TIPO = 'INVESTIMENTOS' THEN C.VALOR END), OUTROS = SUM(CASE WHEN C.TIPO = 'OUTROS' THEN C.VALOR END) FROM @CONTAS AS C GROUP BY C.ANO, C.BANCO
E no SQL Server 2012+, com IIF:
SELECT C.ANO, C.BANCO, INVESTIMENTOS = SUM(IIF(C.TIPO = 'INVESTIMENTOS', C.VALOR, NULL)), OUTROS = SUM(IIF(C.TIPO = 'OUTROS', C.VALOR, NULL)) FROM @CONTAS AS C GROUP BY C.ANO, C.BANCO
Também é possível fazer com subqueries, mas como não é performático, então ignoraremos esta alternativa.
O segundo exemplo, transformamos os registros de anos em colunas respectivas a estes anos, utilizando PIVOT:
SELECT U.BANCO, U.TIPO, U.[2009], U.[2010], U.[2011], U.[2012] FROM @CONTAS AS C PIVOT ( SUM(C.VALOR) FOR C.ANO IN ([2009], [2010], [2011], [2012]) ) AS U
Sem PIVOT, é possível fazer o mesmo procedimento com CASE WHEN:
SELECT C.BANCO, C.TIPO, [2009] = SUM(CASE WHEN C.ANO = 2009 THEN C.VALOR END), [2010] = SUM(CASE WHEN C.ANO = 2010 THEN C.VALOR END), [2011] = SUM(CASE WHEN C.ANO = 2011 THEN C.VALOR END), [2012] = SUM(CASE WHEN C.ANO = 2012 THEN C.VALOR END) FROM @CONTAS AS C GROUP BY C.BANCO, C.TIPO
E no SQL Server 2012+, com IIF:
SELECT C.BANCO, C.TIPO, [2009] = SUM(IIF(C.ANO = 2009, C.VALOR, NULL)), [2010] = SUM(IIF(C.ANO = 2010, C.VALOR, NULL)), [2011] = SUM(IIF(C.ANO = 2011, C.VALOR, NULL)), [2012] = SUM(IIF(C.ANO = 2012, C.VALOR, NULL)) FROM @CONTAS AS C GROUP BY C.BANCO, C.TIPO
E agora, algumas questões que são mais fáceis de resolver com CASE WHEN e IIF, como criar regras mais específicas para as colunas utilizando outras funções e outras regras de agrupamento:
SELECT U.BANCO, U.TIPO, U.[2008], U.[2009], U.[2010], U.[2011], U.[2012], [2009_2010] = U.[2009] + U.[2010], [2011_2012] = U.[2011] + U.[2012], TOTAL = U.[2009] + U.[2010] + U.[2011] + U.[2012] FROM @CONTAS AS C PIVOT ( SUM(C.VALOR) FOR C.ANO IN ([2008], [2009], [2010], [2011], [2012]) ) AS U SELECT C.BANCO, C.TIPO, [2008] = SUM(CASE WHEN C.ANO = 2008 THEN C.VALOR ELSE 0 END), [2009] = SUM(CASE WHEN C.ANO = 2009 THEN C.VALOR ELSE 0 END), [2010] = SUM(CASE WHEN C.ANO = 2010 THEN C.VALOR ELSE 0 END), [2011] = SUM(CASE WHEN C.ANO = 2011 THEN C.VALOR ELSE 0 END), [2012] = SUM(CASE WHEN C.ANO = 2012 THEN C.VALOR ELSE 0 END), [!2012] = SUM(CASE WHEN C.ANO <> 2012 THEN C.VALOR ELSE 0 END), [<2012] = SUM(CASE WHEN C.ANO < 2012 THEN C.VALOR ELSE 0 END), [2009_2010] = SUM(CASE WHEN C.ANO IN (2009, 2010) THEN C.VALOR ELSE 0 END), [2011_2012] = SUM(CASE WHEN C.ANO BETWEEN 2011 AND 2012 THEN C.VALOR ELSE 0 END), TOTAL = SUM(C.VALOR), MEDIA = AVG(C.VALOR) FROM @CONTAS AS C GROUP BY C.BANCO, C.TIPO SELECT C.BANCO, C.TIPO, [2008] = SUM(IIF(C.ANO = 2008, C.VALOR, 0)), [2009] = SUM(IIF(C.ANO = 2009, C.VALOR, 0)), [2010] = SUM(IIF(C.ANO = 2010, C.VALOR, 0)), [2011] = SUM(IIF(C.ANO = 2011, C.VALOR, 0)), [2012] = SUM(IIF(C.ANO = 2012, C.VALOR, 0)), [!2012] = SUM(IIF(C.ANO <> 2012, C.VALOR, 0)), [<2012] = SUM(IIF(C.ANO < 2012, C.VALOR, 0)), [2009_2010] = SUM(IIF(C.ANO IN (2009, 2010), C.VALOR, 0)), [2011_2012] = SUM(IIF(C.ANO BETWEEN 2011 AND 2012, C.VALOR, 0)), TOTAL = SUM(C.VALOR), MEDIA = AVG(C.VALOR) FROM @CONTAS AS C GROUP BY C.BANCO, C.TIPO
E a composição de um agrupamento de linhas para colunas com considerando mais de uma coluna:
SELECT BANCO = COALESCE(U_I.BANCO, U_O.BANCO), INV_2009 = U_I.[2009], INV_2010 = U_I.[2010], INV_2011 = U_I.[2011], INV_2012 = U_I.[2012], OUT_2009 = U_O.[2009], OUT_2010 = U_O.[2010], OUT_2011 = U_O.[2011], OUT_2012 = U_O.[2012] FROM (SELECT BANCO, ANO, VALOR FROM @CONTAS WHERE TIPO = 'INVESTIMENTOS') AS C_I PIVOT ( SUM(C_I.VALOR) FOR C_I.ANO IN ([2009], [2010], [2011], [2012]) ) AS U_I FULL OUTER JOIN (SELECT BANCO, ANO, VALOR FROM @CONTAS WHERE TIPO = 'OUTROS') AS C_O PIVOT ( SUM(C_O.VALOR) FOR C_O.ANO IN ([2009], [2010], [2011], [2012]) ) AS U_O ON U_I.BANCO = U_O.BANCO
SELECT C.BANCO, INV_2009 = SUM(CASE WHEN C.ANO = 2009 AND TIPO = 'INVESTIMENTOS' THEN C.VALOR ELSE 0 END), INV_2010 = SUM(CASE WHEN C.ANO = 2010 AND TIPO = 'INVESTIMENTOS' THEN C.VALOR ELSE 0 END), INV_2011 = SUM(CASE WHEN C.ANO = 2011 AND TIPO = 'INVESTIMENTOS' THEN C.VALOR ELSE 0 END), INV_2012 = SUM(CASE WHEN C.ANO = 2012 AND TIPO = 'INVESTIMENTOS' THEN C.VALOR ELSE 0 END), OUT_2009 = SUM(CASE WHEN C.ANO = 2009 AND TIPO = 'OUTROS' THEN C.VALOR ELSE 0 END), OUT_2010 = SUM(CASE WHEN C.ANO = 2010 AND TIPO = 'OUTROS' THEN C.VALOR ELSE 0 END), OUT_2011 = SUM(CASE WHEN C.ANO = 2011 AND TIPO = 'OUTROS' THEN C.VALOR ELSE 0 END), OUT_2012 = SUM(CASE WHEN C.ANO = 2012 AND TIPO = 'OUTROS' THEN C.VALOR ELSE 0 END) FROM @CONTAS AS C GROUP BY C.BANCO
SELECT C.BANCO, INV_2009 = SUM(IIF(C.ANO = 2009 AND TIPO = 'INVESTIMENTOS', C.VALOR, 0)), INV_2010 = SUM(IIF(C.ANO = 2010 AND TIPO = 'INVESTIMENTOS', C.VALOR, 0)), INV_2011 = SUM(IIF(C.ANO = 2011 AND TIPO = 'INVESTIMENTOS', C.VALOR, 0)), INV_2012 = SUM(IIF(C.ANO = 2012 AND TIPO = 'INVESTIMENTOS', C.VALOR, 0)), OUT_2009 = SUM(IIF(C.ANO = 2009 AND TIPO = 'OUTROS', C.VALOR, 0)), OUT_2010 = SUM(IIF(C.ANO = 2010 AND TIPO = 'OUTROS', C.VALOR, 0)), OUT_2011 = SUM(IIF(C.ANO = 2011 AND TIPO = 'OUTROS', C.VALOR, 0)), OUT_2012 = SUM(IIF(C.ANO = 2012 AND TIPO = 'OUTROS', C.VALOR, 0)) FROM @CONTAS AS C GROUP BY C.BANCO
Olá pessoas,
A mágica de transformar linhas em colunas no SQL Server com PIVOT não é tão simples, o que requer um pouco de domínio de T-SQL, para saber como utiliza-la, além de não ser pego por alguns erros comuns.
Neste primeiro artigo, vou apresentar alguns exemplos simples, e apresentar um problema comum de se trabalhar com PIVOT.
De início, temos uma massa de dados:
DECLARE @CONTAS TABLE ( ANO SMALLINT, BANCO VARCHAR(100), TIPO VARCHAR(100), VALOR MONEY ) INSERT INTO @CONTAS VALUES (2009,'BANCO ALVORADA S/A','INVESTIMENTOS',6175979775.42), (2010,'BANCO ALVORADA S/A','INVESTIMENTOS',6486892688.53), (2011,'BANCO ALVORADA S/A','INVESTIMENTOS',7905663406.86), (2012,'BANCO ALVORADA S/A','INVESTIMENTOS',9613906084.01), (2009,'BANCO ARBI S/A','INVESTIMENTOS',8102644.84), (2009,'BANCO ARBI S/A','OUTROS',174343.35), (2010,'BANCO ARBI S/A','INVESTIMENTOS',7935411.15), (2010,'BANCO ARBI S/A','OUTROS',119885.82), (2011,'BANCO ARBI S/A','INVESTIMENTOS',8202652.29), (2011,'BANCO ARBI S/A','OUTROS',114215.13), (2012,'BANCO ARBI S/A','INVESTIMENTOS',8407843.72), (2012,'BANCO ARBI S/A','OUTROS',81746.25) SELECT ANO, BANCO, TIPO, VALOR FROM @CONTAS
Para criar transformar as linhas de contas do tipo ‘INVESTIMENTOS’ e ‘OUTROS’ em linhas com uma coluna com os valores respectivos a ‘INVESTIMENTOS’ e outra a ‘OUTROS’, utilizaremos a expressão PIVOT sobre a tabela @CONTAS, somando os valores da coluna ‘VALOR’ para onde a coluna ‘TIPO’ apresenta os valores ‘INVESTIMENTOS’ e ‘OUTROS’, assim temos a primeira consulta e resultado:
SELECT U.ANO, U.BANCO, U.INVESTIMENTOS, U.OUTROS FROM @CONTAS AS C PIVOT ( SUM(VALOR) FOR TIPO IN (INVESTIMENTOS, OUTROS) ) AS U
![]()
Desta forma, os registros da tabela @CONTAS se transformam na PIVOT com o alias/apelido U (pode ser outra alias, sem problemas), assim as colunas TIPO e VALOR deixaram de existir, e são agrupadas por ANO e BANCO nas colunas INVESTIMENTOS e OUTROS.
Obs.: Não é obrigatório especificar as colunas no SELECT, pois ele só reconhecerá as colunas do alias U, mas especifiquem para ficar organizado.
Abaixo, um exemplo utilizando a coluna VALOR agrupada por BANCO e TIPO para cada um dos anos da coluna ANO:
SELECT U.BANCO, U.TIPO, U.[2009], U.[2010], U.[2011], U.[2012] FROM @CONTAS AS C PIVOT ( SUM(C.VALOR) FOR C.ANO IN ([2009], [2010], [2011], [2012]) ) AS U
![]()
Uma preocupação que se deve ter ao utilizar PIVOT é especificar claramente as colunas que serão agrupadas e quais as colunas que não serão, pois o SQL Server ainda não lê pensamentos, o que gera um erro bem comum, como apresentado abaixo.
“Então, estou com aquele script de PIVOT (A), mas quando removi a coluna ANO, para agrupar pelas colunas BANCO, INVESTIMENTOS e OUTROS, mas não deu certo, começou a aparecer duplicado a coluna BANCO (B).”
(A):
SELECT U.BANCO, U.INVESTIMENTOS, U.OUTROS FROM @CONTAS AS C PIVOT ( SUM(VALOR) FOR TIPO IN (INVESTIMENTOS, OUTROS) ) AS U
(B):
![]()
Este problema se dá ao fato, que independente de você tirar as colunas especificadas no SELECT, a PIVOT continuará sendo feita sobre todas as colunas da tabela, ou seja, tirou a coluna ‘ANO’ do SELECT, não quer dizer que a PIVOT vai esquecer que a coluna ‘ANO’ existe.
Para evitar este problema, ao invés de utilizar diretamente a tabela para a PIVOT, especifique em uma subconsulta, quais colunas a PIVOT utilizará, exemplo:
SELECT U.BANCO, U.INVESTIMENTOS, U.OUTROS FROM ( SELECT BANCO, TIPO, VALOR FROM @CONTAS ) AS C PIVOT ( SUM(C.VALOR) FOR C.TIPO IN (INVESTIMENTOS, OUTROS) ) AS U
![]()
Próximas semanas, eu vou apresentar o UNPIVOT e também ensinar as limitações destas cláusulas e mágicas, assim como explicar como fazer as mesmas coisas sem utilizar PIVOT e UNPIVOT.
 http://www.sqlfromhell.com/entendendo-except-intersect-e-union-do-sql/
http://www.sqlfromhell.com/entendendo-except-intersect-e-union-do-sql/







